class: middle, center, title-slide .center[.width-60[]] # AI Black Belt - Yellow Day 2/4: Learn to identify and solve supervised learning problems <br><br><br> --- class: middle ## Outline .inactive[[Day 1] Introduction to machine learning with Python] [Day 2] Learn to identify and solve supervised learning problems - Learn to recognize classification and regression problems in the wild. - Practice classification algorithms with Scikit-Learn. .inactive[[Day 3] Practice regression algorithms for sentiment analysis] .inactive[[Day 4] Learn how to let the machine tune itself] --- class: middle # Supervised learning --- class: middle .center.width-100[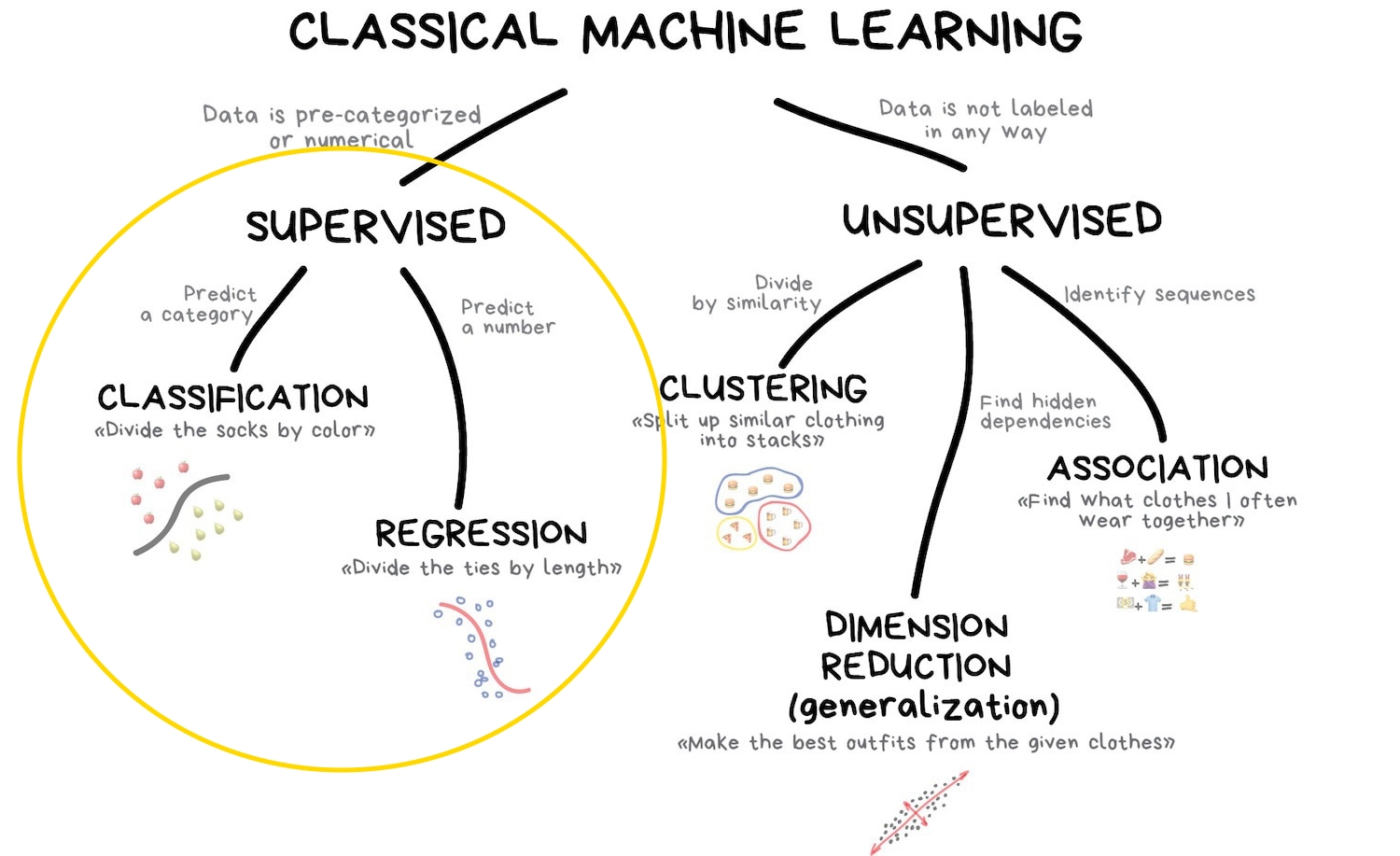] .footnote[Credits: vas3k, [Machine Learning for Everyone](https://vas3k.com/blog/machine_learning/), 2018.] --- # Representing data <br> .center.width-100[] .footnote[Credits: Andreas Mueller, [Introduction to Machine Learning with Scikit-Learn](https://github.com/amueller/ml-workshop-1-of-4/), 2019.] --- # Supervised learning .center.width-70[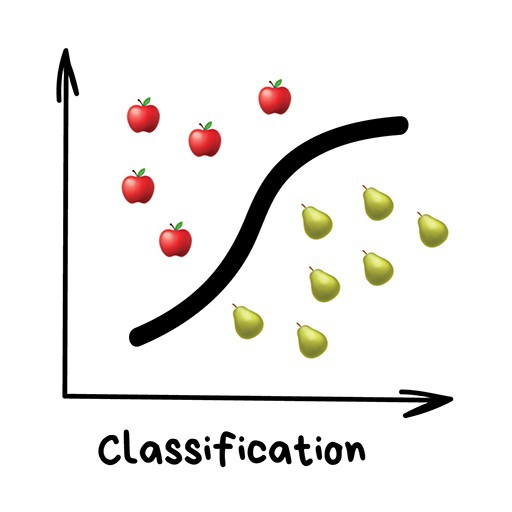] .footnote[Credits: vas3k, [Machine Learning for Everyone](https://vas3k.com/blog/machine_learning/), 2018.] --- class: middle .center.width-70[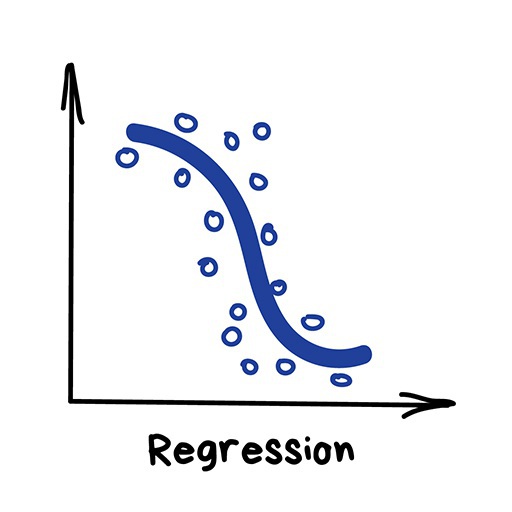] .footnote[Credits: vas3k, [Machine Learning for Everyone](https://vas3k.com/blog/machine_learning/), 2018.] --- class: middle Formally, given inputs $\mathbf{X}$ and outputs $\mathbf{y}$, we want to find a function $f$ such that $$\mathbf{y} \approx f(\mathbf{X}).$$ - in classification, the set of possible output values is finite and *symbolic*. - in regression, the set of possible output values is infinite and **numerical**. --- # In the wild .grid[ .kol-1-2[ ## Classification - Visual recognition - Spam filtering - Sentiment analysis - Medical diagnosis - Weather forecast - Customer segmentation - Recommendations ] .kol-1-2[ ## Regression - Weather forecast - Stock price forecast - Demand and sales volume analysis - Estimating the price of an Uber ride - Market value prediction - Playing games ] ] .exercice[Can you think of more examples?] --- class: middle .exercice[Is this a classification or a regression problem? What are the inputs and outputs?] --- class: middle, center, black-slide .width-45[] .width-45[] Would he survive the sinking of the Titanic? --- class: middle, center, black-slide .width-55[] .width-55[] Sorting cucumbers? --- class: middle, center, black-slide .width-80[] How long will it take to arrive at work if you leave home at 6:00 AM? --- class: middle, center, black-slide .width-80[] Are you sick? --- class: middle, center, black-slide .width-80[] What's the market value of my house? --- class: middle .exercice[Identify supervised learning problems for each of the following situations. What are the inputs and outputs? Brainstorm in small groups.] --- class: middle, black-slide .center.width-80[] .footnote[Credits: Andreas Mueller, [Introduction to Machine Learning with Scikit-Learn](https://github.com/amueller/ml-workshop-1-of-4/), 2019.] --- class: middle, black-slide .center.width-80[] .footnote[Credits: Andreas Mueller, [Introduction to Machine Learning with Scikit-Learn](https://github.com/amueller/ml-workshop-1-of-4/), 2019.] --- class: middle, center, black-slide .width-80[] --- class: middle, center, black-slide .width-80[] --- class: middle, center, black-slide .width-40[] --- class: middle, center, black-slide .width-80[] --- class: middle # Classification --- # Recap .grid[ .kol-1-2[ <br><br><br><br> ## Estimator API ```python clf = RandomForestClassifier() clf.fit(X_train, y_train) y_pred = clf.predict(X_test) clf.score(X_test, y_test) ``` ] .kol-1-2[ .center.width-100[] ] ] --- class: middle Jump to `day2-01-scikit-learn.ipynb`. [](https://mybinder.org/v2/gh/AI-BlackBelt/yellow/master) --- # Choosing the right estimator <br><br> .center.width-100[] --- class: middle ## Linear model Model the decision boundary as a hyperplane. .center.width-60[] .footnote[Credits: vas3k, [Machine Learning for Everyone](https://vas3k.com/blog/machine_learning/), 2018.] --- class: middle .center.width-100[] ```python from sklearn.linear_model import LogisticRegression clf = LogisticRegression() clf.fit(X, y) ``` --- class: middle ## K-Nearest neighbors Predict the average output value among the $K$ closest neighbors to the input $\mathbf{x}$. Closeness is typically defined using the Euclidean distance. .center.width-50[] .footnote[Credits: Andreas Mueller, [Introduction to Machine Learning with Scikit-Learn](https://github.com/amueller/ml-workshop-1-of-4/), 2019.] --- class: middle .exercice[Practice K-Nearest neighbors in the classroom.] --- class: middle .center.width-100[] ```python from sklearn.neighbors import KNeighborsClassifier clf = KNeighborsClassifier(n_neighbors=5) clf.fit(X, y) ``` --- class: middle ## Decision trees Idea: build a partition of the input space using cuts orthogonal to feature axes. .center.width-100[] .footnote[Credits: vas3k, [Machine Learning for Everyone](https://vas3k.com/blog/machine_learning/), 2018.] --- class: middle .center.width-100[] ```python from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier() clf.fit(X, y) ``` --- class: middle ## Naive Bayes (optional) Idea: apply the Bayes rule to make predictions for $y$ given $\mathbf{x}$. .center.width-100[] .footnote[Credits: vas3k, [Machine Learning for Everyone](https://vas3k.com/blog/machine_learning/), 2018.] --- class: middle .center.width-100[] ```python from sklearn.naive_bayes import GaussianNB clf = GaussianNB() clf.fit(X, y) ``` --- # Preprocessing Not only the performance on your system depends on the algorithm you pick, but also on how you **prepare** the data. - How should you treat missing values? - How do you encode categorical/symbolic features into numerical values? - Does the scale of the features matter? <br> .center.width-50[] .center.italic[Garbage in, garbage out.] --- class: middle ## Transformer API ```python tf = StandardScaler() tf.fit(X_train) X_train_scaled = tf.transform(X_train) X_test_scaled = tf.transform(X_test) ``` <br> .center.width-50[] --- class: middle Jump to - `day2-02-census.ipynb`. - `day2-03-challenge.ipynb` [](https://mybinder.org/v2/gh/AI-BlackBelt/yellow/master)